
Por outro lado, muitos desenvolvedores e DBA’s utilizam ferramentas do Query Analyzer como o ShowPlan gráfico, SHOWPLAN_ALL ou SHOWPLAN_TEXT, mas a próxima pergunta é : O que devemos procurar quando examinamos o resultado do plano de execução de uma query?
Neste artigo descreverei algums pontos importantes nos quais você deve estar atento na hora de analisar o plano de execução de uma query. Para isto, estarei utilizando o Showplan gráfico do Query Analyzer. Sendo assim, para aqueles que não conhecem o SHOWPLAN, recomendo a leitura dos tópicos “SET SHOWPLAN_ALL“, “SET SHOWPLAN_TEXT” e “Graphically Displaying the Execution Plan Using SQL Query Analyzer” no Books Online.
Em resumo, para ver o plano de execução de uma consulta no Query Analyzer, basta escrever a query e teclar Ctrl+L ou clicar no botão Display Estimated Execution Plan na barra de ferramentas do Query Analyzer.
É importante observar que, uma vez que os problemas de performance podem ter várias razões e consequentemente várias soluções, os pontos destacados aqui são pontos básicos que você deve analisar e na medida do possível evitar que aconteçam.
Primeiro Ponto: Operações com alto percentual de consumo
Em uma query simples, inicie procurando por operações que geram um alto percentual de consumo. Procurar por operações de alto consumo permitirá que você priorize qual problema deverá ser atacado primeiro.
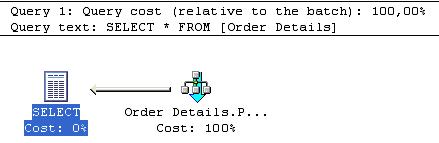
Se você esta analisando uma query com multiplos statements, será gerado um plano de execução separado para cada statement. Para cada plano de execução será mostrado a ordem de execução da query, por exemplo: Query 1, Query 2 e seu respectivo custo. Neste caso, procure pelas queries com maior custo.
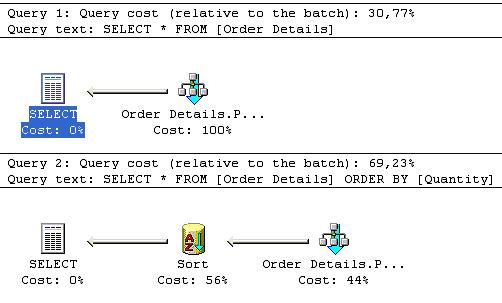
Lembre-se : O plano de execução sempre deve ser lido da direita para a esquerda e de cima para baixo !!
Segundo ponto: Table Scan, Index Scans e Clustered Index Scans

Table Scans, Index Scans e Clustered Index Scans são operações que navegam por todas as linhas da tabela ou do índice e retornam as linhas que satisfazem a cláusula WHERE (assumindo que você use uma cláusula WHERE).
Um Table Scan obtém linhas de uma tabela não indexada, conhecida também como heap table. Um Index Scan procura por linhas no índice não cluster, enquanto que um clustered index scan procura por linhas no índice cluster de uma tabela.
É importante destacar que os Scans nem sempre são ruins, principalmente quando em tabelas com um pequeno número de registros ou consultas que devem retornar todos os registros de uma tabela. Scans podem ser ruins se sua consulta roda por um período muito longo vindo a prejudicar inclusive outras conexões, causando o que chamamos de blocks.
Os Scans são em sua maioria resolvidos através da criação de índices apropriados. Algumas soluções incluem alterar suas consultas de forma a ser mais seletiva, ou seja, usar a cláusula WHERE para filtrar ao máximo possível os registros retornados, adicionar/remover e modificar índices, remover hints, alterar o desing da tabela e usar a ferramenta Index Tuning Wizard para lhe auxiliar na criação de possíveis índices.
Terceiro ponto: Warnings
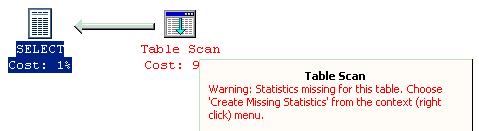
Warings ou alertas normalmente são vistos quando não existem estatísticas para colunas de uma tabela e essas colunas são utilizadas como filtros de pesquisa nas queries. Eles podem ser solucionados através da criação de estatísticas para a coluna afetada (CREATE STATISTICS) ou ainda, criação de índices e adição de cláusulas JOIN.
Quarto ponto: Seta muito grossa
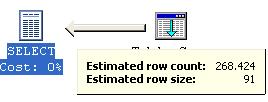
As setas não são operadores, elas simplesmente são usadas para ligar um operador a outro. Através das setas podemos ter uma estimativa da quantidade de linhas afetadas por uma query, isto porque, quanto maior a expessura da seta, maior é a quantidade de linhas envolvidas na operação. Ou se preferir, a quantidade de linhas passada de um operador para outro.
Para que você possa ver a estimativa de quantidade e tamanho das linhas afetadas, basta posicionar o cursor sobre a seta.
Neste senário, sempre dê uma atenção especial às setas mais grossas, pois uma linha muito grossa pode indicar uma alta operação de I/O.
Para solucionar este tipo de problema você deve tentar fazer com que as setas fiquem o mais fina possível e aqui novamente entra a cláusula WHERE. Por outro lado, evite obter mais linhas que o necessário.
Quinto Ponto: Bookmark Lookups
O operador Bookmark Lookup ocorre em conjunto com um nonclustered index seek quando a consulta deve obter colunas que não estão disponíveis dentro do nonclustered index. Neste senário, procure por Bookmark Lookup que possua um alto percentual de consumo.
Se o custo da operação de Bookmark Lookup for muito alto, verifique se um índice cluster ou um índice não cluster composto pelas devidas colunas (covering index) pode ser utilizado.
Sexto Ponto: Sorting

Um operador SORT ordena todas as linhas de entrada em uma ordem ascendente ou descendente. Isto depende da cláusula ORDER BY de sua consulta.
Operadores Sort normalmente acrescentam uma grande taxa de I/O às operações, primariamente utilizando o TEMPDB para suas operação.
Se você costuma ver o operador SORT com muita frequência em suas consultas e este operador possui um alto consumo de operação, considere por remover a cláusula ORDER BY. Por outro lado, se você sabe que sempre ordenará sua consulta por uma coluna em específico, considere indexá-la. Lembre-se que no comando CREATE INDEX você pode fixar a direção de ordenação (ASC ou DESC) para um índice em particular.
Nota: O Profiler é uma excelente ferramena para ajudar na identificação de queries muito pesadas ou que possuem um alto tempo de execução.